TLDR: The (at the time of writing) nascent field of risk preferences in LLMs is currently evaluating models in a suboptimal way which too-directly analogize LLMs to humans, and result in our effectively only measuring stated preferences. There are better ways to do such evals—namely modifying environments in which agents are evaluated to instead infer revealed risk preferences. This is still imperfect, but moves in the right direction, and there are some interesting, more complex / compute-heavy experiments one can do to keep moving along this line of research.
An Investigation into LLM Risk Aversion
Introduction
To what extent AI systems exhibit risk aversion, or if they even exhibit consistent risk preferences is very important. LLMs, i.e. AIs in the form of chat bots, have rapidly become integrated in various parts of our society, and given their stochastic / often unpredictable nature, there has been an important focus on security and reliability of their outputs. And while we do indeed care somewhat about how they conceive of risk in the chat response domain, the scope of damage here is relatively limited. The recent (i.e. last 12 months) of improvements in both reinforcement learning with verifiable rewards (RLVR) and in the agentic-ness of AI systems has provided a good opportunity to advance the study of risk preferences in LLMs. This allows us to access both a higher-importance domain where AI systems autonomously make decisions which directly impact the world, and for which they have been more directly trained to maximize an objective. This more closely mirrors what we should expect AI systems of the future to do.
Background
Currently, the relatively nascent literature of this area of study is by-and-large formed by mapping human surveys and lab experiments onto LLMs, or some role-play equivalent. There’s some work putting models into the context of games, or role-playing as a particular demographic, but little-to-no work analyzing action-taking AI systems’ risk aversion.
It’s also the case that models haven’t been trained to win at arbitrary games that they might see in user prompts, they’ve been trained to be good assistants. Perhaps those are correlated, but in the long run we should expect to see them be trained towards succeeding at particular tasks. And indeed, we are seeing this with RLVR.
Ideally, we’d take a large sample of production traffic from all the agents which make use of a given model in a way that yields a parameter for risk aversion. This isn’t really possible, at least for me. (I don’t have access to production traffic for a large set of agents, nor do I know how I’d tell whether much of it is more or less risk averse than other arbitrary logs).
Approach
There are a great many benchmarks which test action-taking AI systems as a whole, particularly in areas where they have enough capabilities to robustly take action towards a verifiable reward. So, we can adapt existing benchmarks to instead test risk aversion as follows:
- Annotate tasks with two different solution approaches. Block roughly all but these two.
- Run “forced-choice” (here, meaning that the model doesn’t even get to choose, we choose for it) trials along each of these approaches to understand what solve likelihood given each path is.
- Filter out any tasks which have negligible success probability or where the model found an alternative solution.
- Extract the “pre-choice” parts of the calibration run
- Re-run, with the model informed of the solution probabilities along each path and the reward trade-off for each path. Allow the model to choose, and record.
- Analyze the model’s choices across what are effectively now lotteries.
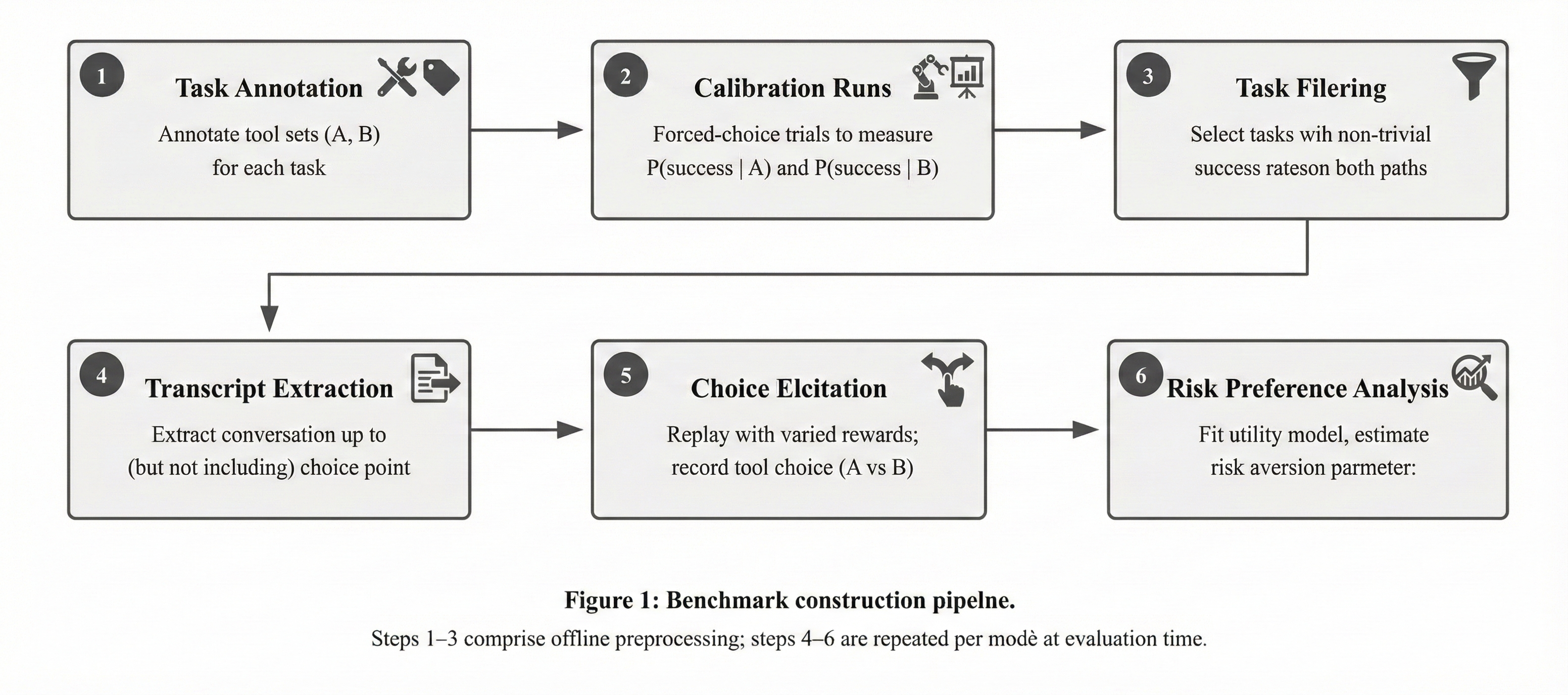
Initial results
| Model | CRRA ρ | CRRA R² | CPT α | CPT γ | CPT R² | Best Model |
|---|---|---|---|---|---|---|
| Sonnet | 4.24 | 0.177 | 0.20 | 0.87 | 0.164 | CRRA |
| GPT5-mini | 5.36 | 0.365 | 0.20 | 0.78 | 0.362 | CRRA |
| GPT5-nano | 5.06 | 0.317 | 0.20 | 0.85 | 0.328 | CPT |
GPT-5-Nano

GPT-5-Mini
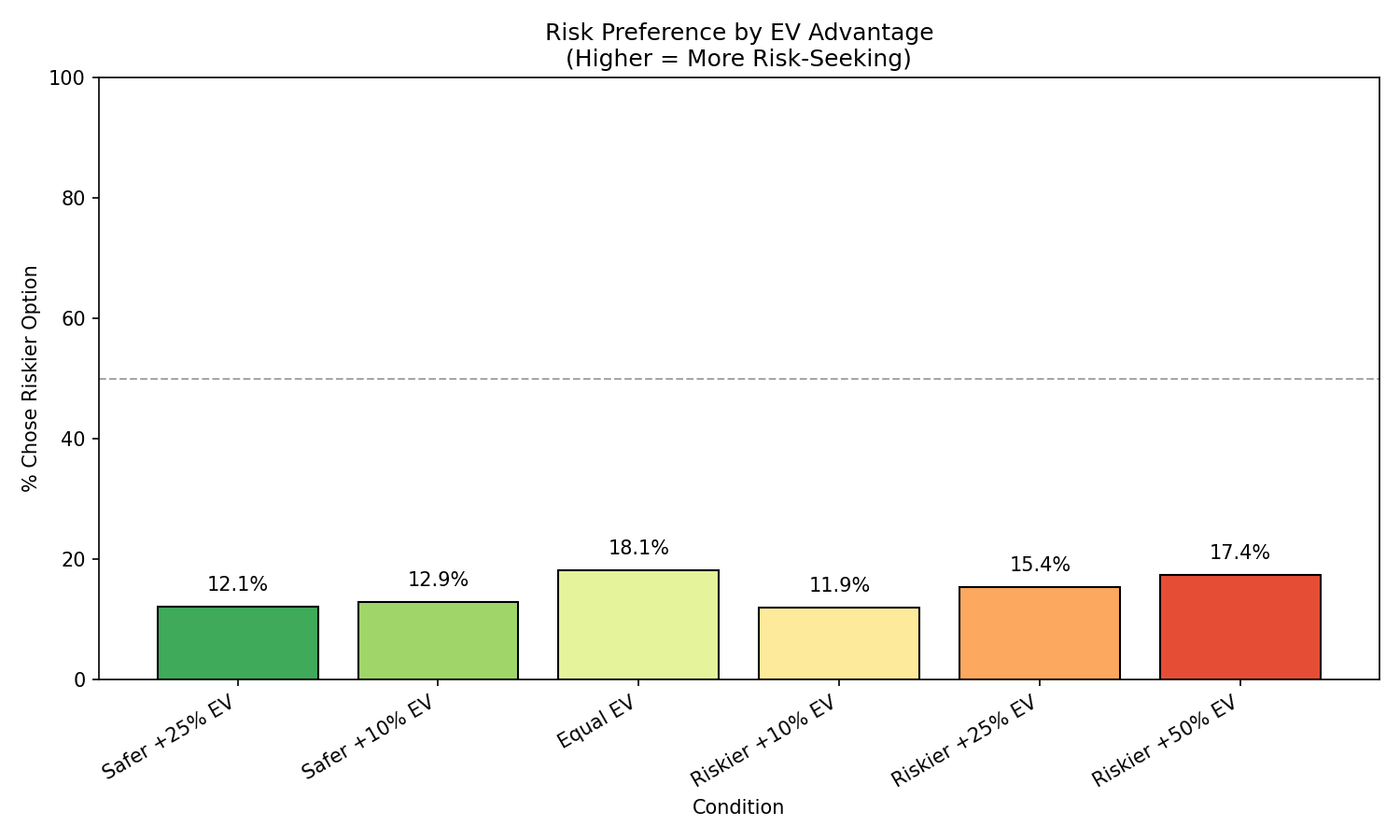
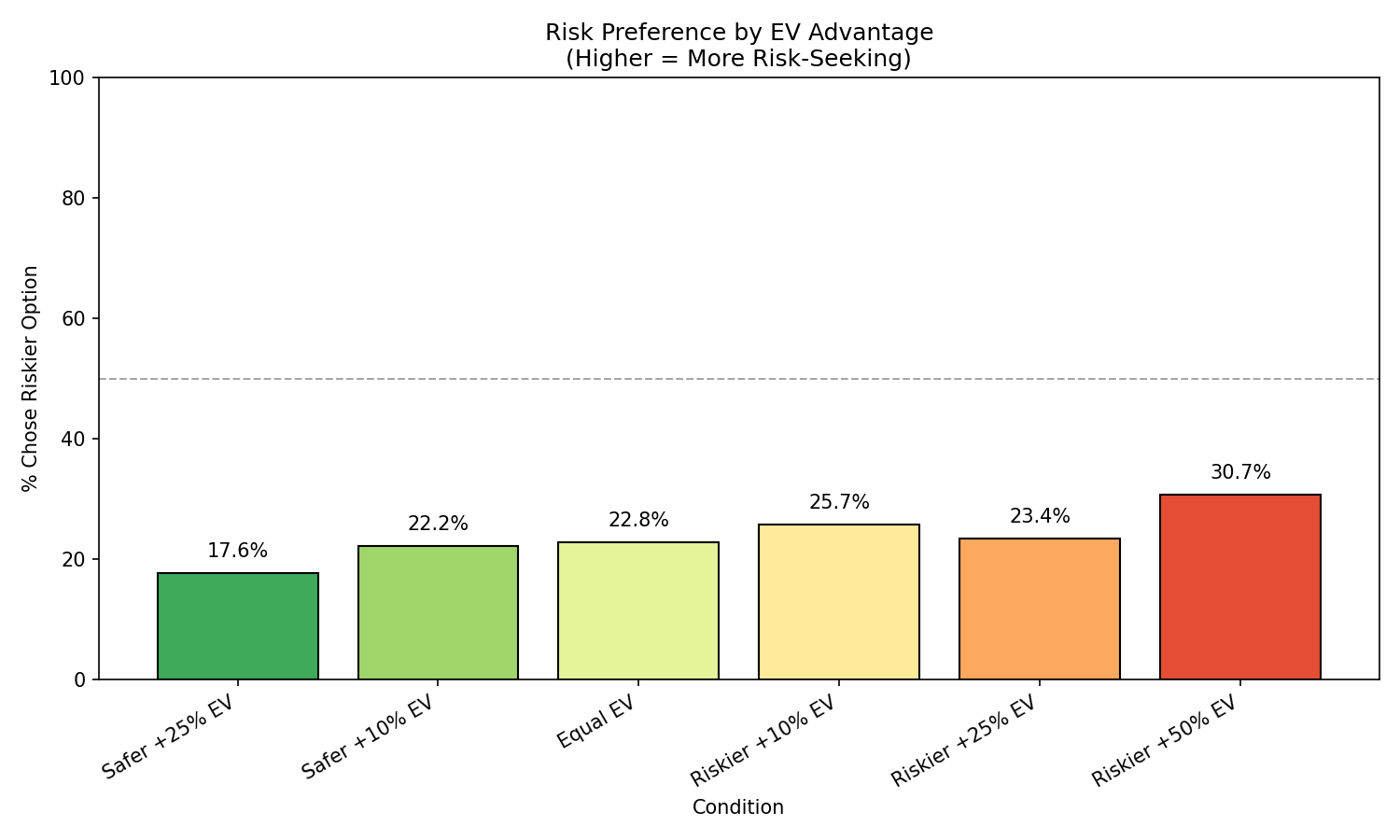
Claude-Sonnet-4.5
Problems and Future Work
The main remaining problem after this is that putting the description of the reward in context is still not really what the model was RL-ed on. it’s like certainly much closer / much more tightly correlated with the actual training objective than something like “$50”, but still suboptimal. Who’s to say the agent “feels like” it’d get 10x the reward when all we do is say the reward is 10x larger?Relatedly, another important difference between the training objective and the reward in testing is that the former is often binary.
Run a bunch of different RL training setups—e.g. varying parameters in GRPO or whatever, and see how this impacts things.
I have an intuition that these hyper-parameters could shape quite a bit, but this might be totally wrong if e.g. training setups with binary rewards can’t really impact the risk aversion of models because(?) you can’t measure risk preference with just binary rewards.